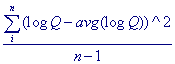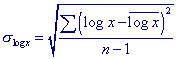| |
 |
||||||||
Analysis Techniques: Flood Frequency AnalysisView and print this webpage as a pdf file. What is it? Flood frequency analyses are used to predict design floods for sites along a river. The technique involves using observed annual peak flow discharge data to calculate statistical information such as mean values, standard deviations, skewness, and recurrence intervals. These statistical data are then used to construct frequency distributions, which are graphs and tables that tell the likelihood of various discharges as a function of recurrence interval or exceedence probability. Flood frequency distributions can take on many forms according to the equations used to carry out the statistical analyses. Four of the common forms are: Each distribution can be used to predict design floods; however, there are advantages and disadvantages of each technique. Click on the above links to learn more about each technique. According to the U.S. Water Advisory Committee on Water Data (1982), the Log-Pearson Type III Distribution is the recommended technique for flood frequency analysis. Therefore, this analysis is examined in detail here with a step-by-step tutorial. Log-Pearson Type III DistributionWhat is it? The Log-Pearson Type III distribution is a statistical technique for fitting frequency distribution data to predict the design flood for a river at some site. Once the statistical information is calculated for the river site, a frequency distribution can be constructed. The probabilities of floods of various sizes can be extracted from the curve. The advantage of this particular technique is that extrapolation can be made of the values for events with return periods well beyond the observed flood events. This technique is the standard technique used by Federal Agencies in the United States. How is it calculated? The Log-Pearson Type III distribution is calculated using the general equation: where x is the flood discharge value of some specified probability,
and
Next, the skewness coefficient Cs can be calculated as follows:
where n is the number of entries, x the flood of some specified probability
and The skewness estimate (Cs) computed using the equation above is called the station estimate, meaning that the estimate incorporates data values only from the gaging station of interest. Error and bias in the skewness estimate increase as the number of observations (n) decreases. The Bulletin 17B method recommended by the Interagency Advisory Committee on Water Data (IACWD) uses a generalized estimate of the coefficient of skewness, Cw (for instantaneous peak flow data only), based on the equation: Cw = WCs + (1-W)Cm where W is a weighting factor, Cs is the coefficient of skewness computed using the sample data, and Cm is a regional skewness, which is determined from a map. The weighting factor W is calculated to minimize the variance of Cw, where
Determination of W requires knowledge of variance of Cm [V(Cm)] and variance of Cs[V(Cs)]. V(Cm) has been estimated from the map of skew coefficients for the United States as 0.302 (IACWD, 1982). This simplifies the denominator of the above equation by substitution of 0.302 for V(Cm). The variance of the station skew Cs for log Pearson type 3 random variables can be obtained from the results of Monte Carlo experiments by Wallis et al. (1974). They showed that
where
in which | C s | is the absolute value of the station skew (used as an estimate of population skew) and n is the record length in years. The coefficient K is then found using tabulated values according to Cw and the return period for each discharge. For a more detailed description of this method, please refer to the following text:
What does this particular information tell you about your river? The Log-Pearson Type III distribution tells you the likely values of discharges to expect in the river at various recurrence intervals based on the available historical record. This is helpful when designing structures in or near the river that may be affected by floods. It is also helpful when designing structures to protect against the largest expected event. For this reason, it is customary to perform the flood frequency analysis using the instantaneous peak discharge data. However, the Log-Pearson Type III distribution can be constructed using the maximum values for mean daily discharge data. A tutorial and example is supplied for both instantaneous and mean daily data.
|
||||||||
| This website was developed by Oregon State University's Civil, Construction, and Environmental Engineering Department with support from the state water institutes program of the U.S. Geological Survey. | |
| Copyright © 2002-2005 Oregon State University -
Web Disclaimer Web Address: http://water.oregonstate.edu/streamflow/ Send Comments to: Peter Klingeman |